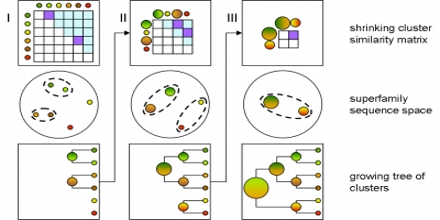
Sequence clustering algorithms attempt to group biological sequences that are somehow related. The sequences can be either of genomic, “transcriptomic” or protein origin. For proteins, homologous sequences are typically grouped into people. For EST data, clustering is crucial that the group sequences caused by the same gene before the ESTs are set up to reconstruct the original mRNA.
Sequence Clustering