As the number of products being sold online increases, it is becoming increasingly difficult for customers to make purchasing decisions based on only pictures and short product descriptions. On the other hand, customer reviews, particularly the text describing the features, comparisons and experiences of using a particular product provide a rich source of information to compare books and make purchasing decisions. Different customers may be interested in different types of books, and their preferences may vary accordingly. In this report, we present a feature-based book ranking technique that mines thousands of customer reviews. We first identify book features within a product category and analyze their frequencies and relative usage. For each feature, we identify subjective and comparative sentences in reviews. We then assign sentiment orientations to these sentences. For implementing our idea we consider our whole work in three phases. These three phases are- backend design, frontend design and text mining. Here backend is designed with SQL Server 2008, front end is in ASP.NET and Microsoft Word is used like other helping tools.
Definition of Database
A database is a set of data that has a regular structure and that is organized in such a way that a computer can easily find the desired information.
Data is a collection of distinct pieces of information, particularly information that has been formatted (i.e., organized) in some specific way for use in analysis or making decisions.
A database can generally be looked at as being a collection of records, each of which contains one or more fields (i.e., pieces of data) about some entity (i.e., object), such as a person, organization, city, product, work of art, recipe, chemical, or sequence of DNA. For example, the fields for a database that is about people who work for a specific company might include the name, employee identification number, address, telephone number, date employment started, position and salary for each worker.
Merits & Demerits of Databases
Merits:
- Shared data.
- Centralized control.
- Disadvantages of redundancy control.
- Improved data integrity.
- Improved data security.
- Flexible conceptual design.
Demerits:
- Highly dependent DBMS operations.
- A complex conceptual design process.
- The need for multiple external databases.
- The need to hire database-related employees.
- High DBMS acquisition costs.
- A more complex programmer environment.
- Potentially catastrophic program failures.
- A longer running time for individual applications
Definition of Entity
Entity is a thing or object that is distinguishable from all other objects.
Example: User, Book, Category etc.
Definition of Attribute
Attributes are descriptive properties possessed by entity.
Example: Book_Id, Title etc of a Book Entity
Parts of Database Design
- ER Diagram
- Relational Model (Table Schemas)
- Normalization of Tables
- Implementation in SQL Server
- Sample Queries
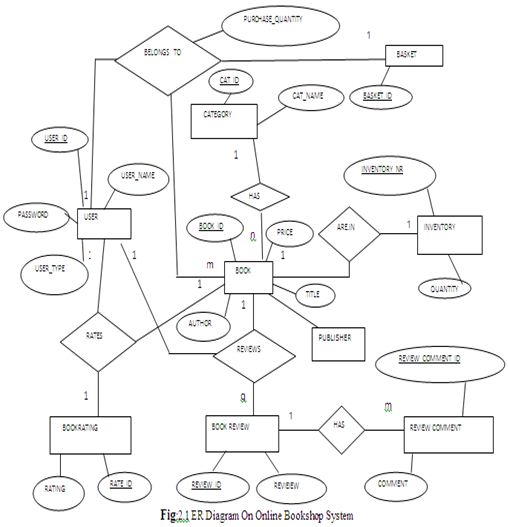
ER Diagram on Online Bookshop System
Mapping Cardinality / Cardinality Ratio
In set theory, cardinality refers to the number of members in the set. In the Data Model context, cardinality defines the numeric relationships between occurrences of the entities on either end of the relationship line. It can also be define as, it express the number of entities to which another entity is associated via a relationship.
There can be many types of relationships like one-to-one, one-to-many, and many-to-many. Explanation based on the set theory is given below.
One-to-one Cardinality Ratio:
An entity in A is associated with almost one entity in B. An entity in B is associated with almost one entity in A.
One to many Cardinality Ratio:
An entity in A is associated with any number of entities in B. An entity in B is associated with at most one entity in A.
Many to many Cardinality Ratio:
An entity in A is associated with any number of entities in B. An entity in B is associated with any number of entities in A.
Degree of Relationship Type
In reality only two entities are related together or more than two entities are related together. This kind of situation is defined by “degree of a relationship” type. Thus, it defines how many entity types are related with a relationship type.
Binary relationship: In this relationship type only two entity types are related with a relationship type.
Ternary relationship: In this relationship type, three entities (not two and not four) are related with a relationship type.
Cardinality for Binary Relationship
Binary relationships are relationships between exactly two entities. The cardinality ratio specifies the maximum number of relationship instances that an entity can participate in. The possible cardinality ratios for binary relationship types are: 1:1(one to one), 1:N (one to many), N:1(many to one), M:N(many to many). Cardinality ratios are shown on ER diagrams by displaying 1, M and N on the diamonds. The figure shown closest to an entity, represents the ratio with respect to the figure the other entity has to that entity.
One to one relationship:
One record of entity A is related to one record of entity B and vice versa.
Example:
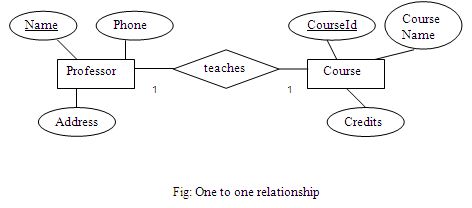
Only one professor can teach a course at a time. A course can be taught by one professor at a time.
One to one relationship is created by including the primary key of a “one” side table as a foreign key (with a synonymous name) in the other “one” side table. The foreign key in turn will be the primary key or part of primary key of the other table.
One to many relationship:
One record of entity A can be related to several (n) records of entity B. But one record of entity B can be related only to one record of entity A.
Example:
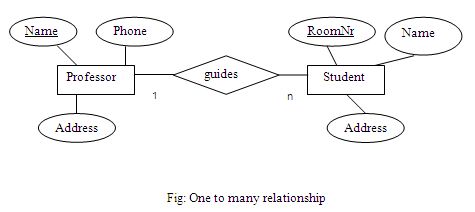
Only one Professor can guide a number of Students at a time. One student can be guided by one professor at a time.
One to many relationship is created by including the primary key of the “one” (parent) table as a foreign key in the “many” (child) table. Many to one relationship is similar to one to many relationship.
Many to many relationship:
One record of entity A can be related to several (n) records of entity B. One record of entity B can be related to several (m) records of entity A.
One student enrolls many courses. One (same) course is enrolled by many students.
Many-to-Many Relationships is created with a new table whose primary key is the combination of the primary keys of the original tables (intersection/junction table).
Cardinality for Ternary Relationship
A ternary relationship is a relationship of degree three. That is, a relationship that contains three participating entities. Cardinalities for ternary relationships can take the form of 1:1:1, 1:1:M, 1:M:N or M:N:P. The cardinality constraint of an entity in a ternary relationship is defined by a pair of two entity instances associated with the other single entity instance. Cardinality ratios are shown on ER diagrams by displaying 1, M and N on the diamonds. The figure shown closest to an entity, represents the ratio with respect to the figure the other entity has to that entity.
One-to-one-to-one ternary relationship:
The 1:1:1 cardinality, in a ternary relationship, is interpreted as indicating a single instance of either X, Y or Z existing only with a single unique pair of instances of the other two entities. That is for a pair of (XY) instances, there is only one instance for Z; for a pair of (XZ) instances, there is only one instance for Y; for a pair of (YZ) instances, there is only one instance of X.
One-to-one-to-many ternary relationship:
A relation having 1:1:M cardinality is simpler since some binary relationships must already be established as 1:M. This is due to the minimum requirements of establishing the initial ternary relation.
Each employee assigned to a project works at only one location for that project, but can be at different locations for different projects. At a particular location, an employee works on only one project. At a particular location, there can be many employees assigned to a given project.
One-to-many-to-many ternary relationship:
Again, a minimum set of instances sufficient to show the cardinality of the ternary relationship (1:M:N), also demonstrates the cardinalities of the individual embedded pairs. Here an example is given.
Each engineer working on a particular project has exactly one manager, but a project supervised by one manager can have many engineers. A manager with one engineer may manage several projects.
Many-to-many-to-many ternary relationship:
The final cardinality combination for a ternary relationship is that of M:N:P. Following the reasoning and proofs given in previous sections, it is easily demonstrated that the minimum set of instances required to show this ternary relationship also must show a M:N relationship between any pair of instances.
Primary Key:
A primary key is a field or a combination of fields that uniquely identify a record in a table, so that an individual record can be located without confusion.
Foreign Key:
A foreign key (sometimes called a referencing key) is a key used to link two tables together. Typically you take the primary key field from one table and insert it into the other table where it becomes a foreign key (it remains a primary key in the original table).
Steps of our ER diagram design
From the above description of different types of cardinality ratio, primary key and foreign key, it helps us to understand the different steps of our ER diagram design.
Pattern of description for different parts of our ERD-
- Cardinality for Binary Relationship we use.
- Cardinality for Ternary Relationship we use.
- Usages of Primary key and foreign key in our ERD.
In our ER diagram we have eight entities that are- USER, BOOKRATING, BOOK REVIEW, REVIEW COMMENT, INVENTORY, CATEGORY & BASKET.
Cardinality ratio usage in our ERD :
Only BOOK and INVENTORY uses 1:1 cardinality ratio. Figure-2.12 shows the relationship below-
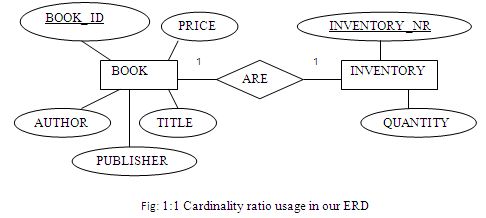
cardinality ratio usage in our ERD :
We use ternary relationship in our ERD. There is only 1:1:1 ternary relationship in online bookshop ER diagram. This is among USER, BOOKRATING & BOOK .Here Figure 2.15 shows the ternary relationship.
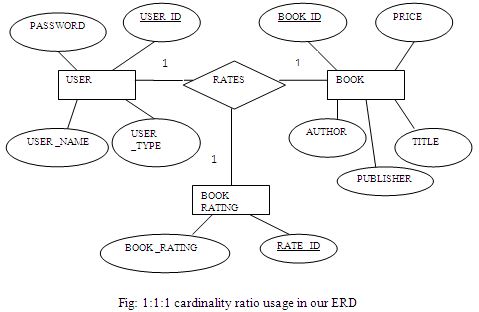
One user rates one rating for one book; one user rates one book with one rating and one book is rated one rating by one user.
Primary key and foreign key description:
Relational model-set of tables based on the above cardinality ratio shown here-
m cardinality ratio uses in our ERD:
In our ERD we have two 1:1: m ternary relations. One is among USER, BOOKREVIEW & BOOK and another is among USER, BASKET & BOOK. Here figure-2.16 & figure-2.17 shows the ternary relationships.
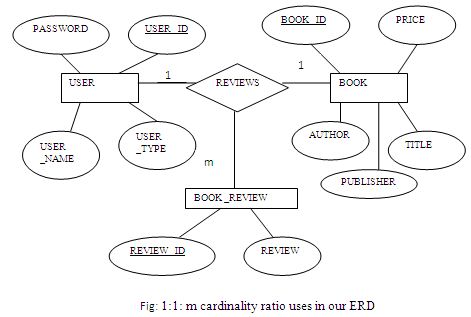
One user reviews for one book many book reviews; one user reviews one book review for one book and one book is reviewed one book review by one user.
Description and Meaning of all attributes from all tables
TABLE: USER
ATTRIBUTES:
1. USER_ID:USER-ID means an id that every user needs to have.
2. USER_NAME:USER-NAME means a name with which a user will want to log in.
3. USER_TYPE:CUSTOMAR-TYPE means type of customers such as “REGULAR”,”VIP”,”CHILDREN” etc.
4. PASSWORD: PASSWORD is needed to log in with USER-NAME.
TABLE: BOOKRATING
ATTRIBUTES:
1. RATE_ID:RATE_ID means the id by which a user can rate a book.
2. RATING:RATING means the quality of a book such as “GOOD”,”BAD”,”BEST”etc.
TABLE: CATEGORY
ATTRIBUTES:
1. CAT_ID: CAT_ID means the id of a specific category.
2.CAT_NAME:CAT_NAME means the name of a category such as “FICTION”,”NOVEL”,”MAGAZINE” etc.
Functional Dependencies
Definition of Full Functional Dependencies: Y is said to be fully functional dependent of X, if there is no proper subset X’ of X. where X’=>Y.
Example: In our university Database
Student (matNr,sName).
{matNr}=>{sName}
Here, two different sName do not correspond to the same matNr.
Normalization
Codd introduce a number of “normal forms”(1970,72).They are principles that can hold for a given relation or not.
Relations can be transformed in order to normalize them.
First Normal Form(1NF)
Definition: A relation is in first normal form if it contains only simple, atomic values for attributes,no sets.
Note: This is what Codd postulated for relations in his model of “normal forms”.
=>All relation in the relation model must be in 1NF.
Second Normal Form (2NF)
Definition:A relation is in 2NF if it is in 1NF and every non primary key attribute is fully functionally dependent on primary key.
Example: In a University Database
TA(matNr,classId,sName,hours,tasalary).
Full Functional dependencies:
{matNr,classId}=>{hours}
{matNr,classId}=>{tasalary}
{matNr}=>{sName}
The relation is not in 2NF.Because part of primary is fully functional dependent on non primary key. To make it 2NF we split the table such as
TA(matNr,classId,hours,tasalary).
Student(matNr,sName).
Now,it is in 2NF.
Transitive Dependency:
A functional dependency X=>Y in a relation R is called a transitive dependency,if R contains a set of attributes,Z,for which holds:
X=>Y=>Z chain exists
a) Y is not a super key or
b) Z is not part of primary key
Z is transitively dependent on X via Y. [3,6]
Third Normal Form(3NF)
Definition:A relation is in 3NF if it is in 2NF and no non primary key attribute is transitively dependent on primary key.
Example:Again our university Database.
TA(matNr,classId,hours,tasalary).
Funtional Dependencies:
{matNr,classId}=>{hours}
{matNr,classId}=>{tasalary}
Assumption:
{hours}=>{tasalary}
There is the following transitive dependency:
{matNr,classId}=>{hours}=>{tasalary}
Since tasalary is not a part of primary key and hours is not a super key.So,this relation is not in 3NF.
To make it 3NF we split:
TA(matNr,classId,hours).
TAnew(hours,tasalary).
Boyce-Codd Normal Form(BCNF)
Definition: BCNF is a little stronger than 3NF.In most cases,relation in 3NF are also in BCNF.For a functional dependency X=>A from attribute X to attribute A if
a) X is not a Superkey and
b) A is part of primary key
The relation is not in BCNF.
Example: Speedlimits(town,streetSegment,postCode,speed).
Full Functional Dependencies:
{town,streetSegment}=>{postcode}
{town,streetSegment}=>{speed}
{postCode}=>{town}
{postcode,streetSegment}=>{speed}
We find:
{town,streetSegment}=>{postCode}=>{town}
Here,postcode is not a super key and town is a part of primary Key.
So,The relation is not in BCNF.
To make it BCNF we split:
Speedlimits(town,streetSegment,speed).
Codes(postcode,town).
Some Notes on Normalization
a)Advantages:
1. Many unnecessary redundancies are avoided.
2. Anomalies with input, deletion and updates can be avoided.
3. Fully normalized, relations occupy less space that if not normalized.
b) Disadvantages:
1. Normalization splits entities and relationships into many relations , thus making them harder to understand.
2. Queries become more complex because they have to involve more relations.
3. Response times are longer because of a higher number of joins in the queries.
Normalization Analysis of Online Bookshop System
1.User(user_id,user_name,password,user_type).
{user_id}=>{user_name}.
Here,two different user_name do not correspond to the same user_id.
{user_id}=>{password}.
Two different password do not correspond to the same user_id.
{user_id}=>{user_type}.
Two different user_type do not correspond to the same user_id.
The attributes have no sub attributes.So it is in 1NF.
Every non primary key is fully functionally dependent on the primary key.It is in 2NF.
The relation is in 2NF and no non primary key attribute is transitively dependent on primary key.So,It is in 3NF.
The relation is in BCNF because no part of primary key is fully functionally dependent on non primary key.
2.Book(book_id,publisher,title,author,price,cat_id(fk)).
{book_id}=>{publisher}.
{book_id}=>{title}.
{book_id}=>{author}.
{book_id}=>{price}.
{book_id}=>{cat_id}.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF .
3.Book Rating(rating_id,rating).
{rating_id}=>{rating}.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF.
4.Category(cat_id,cat_name).
{cat_id}=>{cat_name}.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF .
5.Book Review(review_id,review).
{review_id}=>{review}.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF .
6.Basket(basket_id).
It is 1NF,2NF,3NF,BCNF.
7.Inventory(inventory_nr,quantity).
{inventory_nr}=>{quantity}.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF .
8.ReviewComment(review_comment_id,comment,review_id(fk)).
{review_comment_id}=>{comment}.
{review_comment_id}=>{review_id}.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF .
9.Rates(rate_id,book_id,user_id).
There is no non primary key,so the relation is in
1NF,2NF,3NF, BCNF.
10.Reviews(book_id(fk),review_id,user_id(fk)).
{review_id}=>{user_id}.
{review_id}=>{book_id}.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF.
11.Belongs to(basket_id(fk),user_id(fk),book_id,purchase_quantity).
{book_id}=>{purchase_quantity}
Here same book_id can be with different basket_id and different user_id.
So,these all will be parts of the primary key.
Belongs to(basket_id, user_id, book_id, purchase_quantity).
{basket_id,book_id,user_id}=>{purchase_quantity}
Now,two different purchase_quantity do not correspond to the same basket_id, book_id, user_id.
It is in 1NF.
It is in 2NF.
It is in 3NF.
The relation is in BCNF .
Front End Design
Tools used for Front End Design
Microsoft Visual Studio
Microsoft Visual Studio is an integrated development environment (IDE) from Microsoft. It is used to develop console and graphical user interface applications along with Windows Forms applications, web sites, web applications, and web services in both native code together with managed code for all platforms supported by Microsoft Windows, Windows Mobile, Windows CE, .NET Framework, .NET Compact Framework and Microsoft Silverlight.[7]
ASP.NET
ASP.NET is a Web application framework developed and marketed by Microsoft to allow programmers to build dynamic Web sites, Web applications and Web services. It was first released in January 2002 with version 1.0 of the .NET Framework, and is the successor to Microsoft’s Active Server Pages (ASP) technology. ASP.NET is built on the Common Language Runtime (CLR), allowing programmers to write ASP.NET code using any supported .NET language.
JavaScript
JavaScript is a prototype-based scripting language that is dynamic, weakly typed and has first-class functions. It is a multi-paradigm language, supporting object-oriented, imperative, and functional programming styles.
JavaScript was formalized in the ECMAScript language standard and is primarily used in the form of client-side JavaScript, implemented as part of a Web browser in order to provide enhanced user interfaces and dynamic websites. This enables programmatic access to computational objects within a host environment.
JavaScript’s use in applications outside Web pages — for example in PDF documents, site-specific browsers, and desktop widgets — is also significant. Newer and faster JavaScript VMs and frameworks built upon them (notably Node.js) have also increased the popularity of JavaScript for server-side web applications.
JavaScript uses syntax influenced by that of C. JavaScript copies many names and naming conventions from Java, but the two languages are otherwise unrelated and have very different semantics. The key design principles within JavaScript are taken from the Self and Scheme programming languages.
SQL Server 2008 R2
SQL Server 2008 R2 (formerly codenamed SQL Server “Kilimanjaro”) was announced at TechEd 2009, and was released to manufacturing on April 21, 2010. SQL Server 2008 R2 adds certain features to SQL Server 2008 including a master data management system branded as Master Data Services, a central management of master data entities and hierarchies. Also Multi Server Management, a centralized console to manage multiple SQL Server 2008 instances and services including relational databases, Reporting Services, Analysis Services & Integration Services.
SQL Server 2008 R2 includes a number of new services, including PowerPivot for Excel and SharePoint, Master Data Services, StreamInsight, Report Builder 3.0, Reporting Services Add-in for SharePoint, a Data-tier function in Visual Studio that enables packaging of tiered databases as part of an application, and a SQL Server Utility named UC (Utility Control Point), part of AMSM (Application and Multi-Server Management) that is used to manage multiple SQL Servers.
The first SQL Server 2008 R2 service pack (Service Pack 1) was released on July 11, 2011.
C
C# (pronounced see sharp) is a multi-paradigm programming language encompassing strong typing, imperative, declarative, functional, generic, object-oriented (class-based), and component-oriented programming disciplines. It was developed by Microsoft within its .NET initiative and later approved as a standard by Ecma (ECMA-334) and ISO (ISO/IEC 23270). C# is one of the programming languages designed for the Common Language Infrastructure.
Overview of Online Bookstore
User Manual
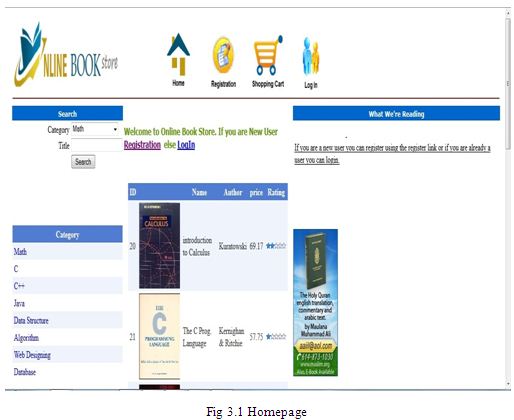
Homepage
For this thesis, we have tried to develop an information management system that supports some of the services involved in an Online Bookstore (e.g., Amazon.com). When we run the Online Book Store Website first home page is displayed. The home page will appear as below. The user and Admin will have different rights. The two login interfaces have the same login function.
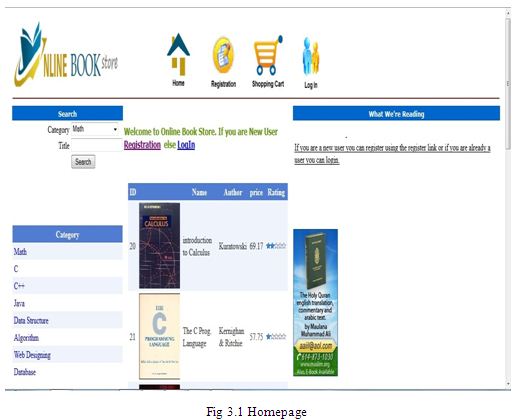
If anyone is a new user s/he can register using the register link or if already a user then he/she can login to purchase book and pay using the checkout.
Any common user can use the search option in the home page to search for a book of his choice by entering a Title of the book.
Registration
A new user can register on the site by clicking on the registration button on the
menu at the top of the page or by clicking on registration link, as shown in Figure 3.1.
The registration page will appear as below.
A user should enter the entire required fields’ information. If he didn’t fill all the fields he/she cannot create an account. After entering all the required data the submit button should be clicked to register. Now one can login to the Website.
Login Website
A registered user can login the site by clicking on Login link as shown in Figure 3.1.
The following page is used to login to the website. The input username is verified whether it exists and it is also verified whether the password is corresponding and then login is allowed.
If any user successfully logins to his/her account then Figure:3.4 page will be shown.
Search a Book
After logging in to the website, a user is eligible to search or buy books as needed. A user is also able to see any book details and place comments on that book.
To search for a book the user can choose the category of the book that he/she wishes to find, or he/she just writes the name of the book in to the title option. After clicking the search button the required book name will be shown. In the case of category based search he/she chooses the category and the result shows the corresponding books that lie on that category.
If the user is interested in any particular book he can click the book image to get the book details as well as place his/her comments corresponding to that book.
Add to Cart
When “Add to Cart” is clicked for any book, it is added to the shopping cart. If that particular book is already present in the shopping cart, the quantity is increased by 1 and the price is changed accordingly; if not, a new entry is made into the table. Here the quantity value should always be a positive value.
The user can also edit his shopping cart details. If he wants to change the quantity or cancel his order he can use this page.
Check Out
After proceeding to checkout the user should enter the billing details to process his order request which is shown in Figure 3.7 below.
Submit Details
After entering the card details the submit button should be clicked to process the order.
Manual
Admin panel
This is Admin’s sign in page. Admin can Sign In by giving the correct AdminID and Password.
Any normal will be considered as a guest and can not sign in. Admin has all the control over this whole site.The main task of Admin is Category Setup,Book Setup,Card Type Setup. Admin can view the Registration information and Order information but can not make any change. One existing Admin can create a new Admin too.We are seeing Home top of right side. By clicking it we can go back home at any time.
Create New Admin
New Admin can be created in this page.
Only one existing Admin can create a new Admin by signing in. To create a new Admin identity we have to give the new AdminID and Password and press Create button.We also showing here the Admin user information.This list shows which Admins are available at present.
Category Setup
In our Book Shop we store books category- wise.This page is for setup of the category of books by category name. After intering the category name we save it by Save button.
We may cancel the name by Cancel button. Existing category names are shown here with the Category Name and ID.We can also edit and delete the category with the option Edit and Delete. All of this is Admin’s work.
Card Type Setup
The Card may be Gold, Premium And Normal. Gold card is for the regular customer who always buy books from us and also give some advanced order for books.
Premiun card is for our registered customers but not the regular buyers. Normal card is also for our registered customer but they do not buy books from us yet. So to set up the card type we have to enter the type and press the SAVE button.We may cancel it by CANCEL button.
Book Setup
Books are setup in this page by Book Name, Author Name, Price, Category Name.The book can also directed by the product Url.
If the book we stored here is any other link then we can browse the link to point the book. Same for the Image Url for the books image.Some notes can also be added when the book is stored by the Notes option.After filling up all the fields we save it by Save button.
Order information
This page shows the order information of a customer.The order information contains Order No., Member ID, First Name of the customer, Address, Card type, Card number, Item,Quantity and the Price.
This information can seen by the Admin only. But the Admin can not make any change here.
Registration Information
The Registration Information of a customer is held in this page.This information is stored here after a cutomer has registered in our shop.
This page contains Member Id,User Name,Level,First Name,Last Name,E-mail,Phone no., Card number, Card type of a customer. Only Admin can see this page not anyone else.
What is Text Mining
Text Mining is the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources. A key element is the linking together of the extracted information together to form new facts or new hypotheses to be explored further by more conventional means of experimentation.
Text mining is different from what we’re familiar within web search. In search, the user is typically looking for something that is already known and has been written by someone else. The problem is pushing aside all the material that currently isn’t relevant to your needs in order to find the relevant information.
In text mining, the goal is to discover heretofore unknown information, something that no one yet knows and so could not have yet written down.
Text mining is a variation on a field called data mining, that tries to find interesting patterns from large databases. A typical example in data mining is using consumer purchasing patterns to predict which products to place close together on shelves, or to offer coupons for, and so on. For example, if you buy a flashlight, you are likely to buy batteries along with it. A related application is automatic detection of fraud, such as in credit card usage. Analysts look across huge numbers of credit card records to find deviations from normal spending patterns. A classic example is the use of a credit card to buy a small amount of gasoline followed by an overseas plane flight. The claim is that the first purchase tests the card to be sure it is active.
The difference between regular data mining and text mining is that in text mining the patterns are extracted from natural language text rather than from structured databases of facts. Databases are designed for programs to process automatically; text is written for people to read. We do not have programs that can “read” text and will not have such for the forseeable future. Many researchers think it will require a full simulation of how the mind works before we can write programs that read the way people do.
However, there is a field called computational linguistics (also known as natural language processing) which is making a lot of progress in doing small subtasks in text analysis. For example, it is relatively easy to write a program to extract phrases from an article or book that, when shown to a human reader, seem to summarize its contents. (The most frequent words and phrases in this section, minus the really common words like “the” are: text mining, information, programs, and example, which is not a bad five-word summary of its contents.)
There are programs that can, with reasonable accuracy, extract information from text with somewhat regularized structure. For example, programs that read in resumes and extract out people’s names, addresses, job skills, and so on, can get accuracies in the high 80 percents.The “real” text mining, that discovers new pieces of knowledge, from approaches that find overall trends in textual data.
As another example, one of the big current questions in genomics is which proteins interact with which other proteins. There has been notable success in looking at which words co-occur in articles that discuss the proteins in order to predict such interactions. The key is to not look for direct mentions of pairs, but to look for articles that mention individual protein names, keep track of which other words occur in those articles, and then look for other articles containing the same sets of words. This very simple method can yield surprisingly good results, even though the meaning of the texts are not being discerned by the programs. Rather, the text is treated like a “bag of words”.
The fundamental limitations of text mining are first, that we will not be able to write programs that fully interpret text for a very long time, and second, that the information one needs is often not recorded in textual form. If I tried to write a program that detected whenever a new word came into existence and how it spread by analyzing web pages, I would miss important clues relating to usage in spoken conversations, email, on the radio and TV, and so on. Similarly, if I tried to write a program that processes published documents in order to guess what will happen to a bill in WashingtonDC, I would fail because most of the action still happens in negotiations behind closed doors.
Applicability of Text Mining
Text Mining Applications are applicable in different areas. Recently, text mining has received attention in many areas.
Security applications
Many text mining software packages are marketed for security applications, especially analysis of plain text sources such as Internet news. It also involves the study of text encryption.
Software and applications
Text mining methods and software is also being researched and developed by major firms, including IBM and Microsoft, to further automate the mining and analysis processes, and by different firms working in the area of search and indexing in general as a way to improve their results. Within public sector much effort has been concentrated on creating software for tracking and monitoring terrorist activities
Online media applications
Text mining is being used by large media companies, such as the Tribune Company, to disambiguate information and to provide readers with greater search experiences, which in turn increases site “stickiness” and revenue. Additionally, on the back end, editors are benefiting by being able to share, associate and package news across properties, significantly increasing opportunities to monetize content.
Marketing applications
Text mining is starting to be used in marketing as well, more specifically in analytical customer relationship management. Coussement and Van den Poel (2008)apply it to improve predictive analytics models for customer churn (customer attrition)
Sentiment analysis
Sentiment analysis may involve analysis of movie reviews for estimating how favorable a review is for a movie.Such an analysis may need a labeled data set or labeling of the affectivity of words. A resource for affectivity of words has been made for WorldNet.
Text has been used to detect emotions in the related area of affective computing. Text based approaches to affective computing have been used on multiple corpora such as students evaluations, children stories and news stories.
Academic applications
The issue of text mining is of importance to publishers who hold large databases of information needing indexing for retrieval. This is especially true in scientific disciplines, in which highly specific information is often contained within written text. Therefore, initiatives have been taken such as Nature’s proposal for an Open Text Mining Interface (OTMI) and the National Institutes of Health‘s common Journal Publishing Document Type Definition (DTD) that would provide semantic cues to machines to answer specific queries contained within text without removing publisher barriers to public access.
Applicability of Text Mining in our work
We apply text mining on a online bookshop in customer’s given comments.Here we store books for selling. A customer can buy a book by seeing its weekly rate or by his own choice. The rating process is given by the customer comment. Here we are applying text mining in customer sentiment analysis (opinion mining). We store some positive and negative words in database tables according to our prediction.When a customer gives a comment we match the words with the stored words. And count the positive and negative comments across the book and give a grade of the book.
Actually a word may have different grammatical format so it is not possible to store all formats of a single word to be stored in the database that’s why we use Porter Stemming Algorithm here to stem a word. Porter Algorithm helps to find only the actual word not its different forms such as past form(ed), continuous form(ing) etc. So, customer can give their comment in any form but we can get the accurate word. This helps to detect the correct forms of the words we need. We also consider some special condition like negation of a positive or negative word and try to consider some other conditions, which emphasize a positive or negative word as customer use in their comments. In these ways we try to understand the customers’ sentiments.
Advantages & Disadvantages of Text Mining
Advantage
- We can analyse lots of text in one structure.
- We can understand the sentiments of customer by analyzing texts.
Disadvantage
- We store some positive and negative words in DB and get match with those words from the customers’ given comments. So the DB storage may get large.
- It is a slow process.
- Our tools can not handle complex sentences.
Such as , although volume upon volume is written to prove this book is very well written,but I never hear of the man who would like to take this book.
It can not evaluate the right sentiment of the sentence.
Implementation of Text Mining
Overview of Stemming Algorithm
The Porter Stemmer is a conflation Stemmer developed by Martin Porter at the University of Cambridge in 1980. The Porter stemmer is a context sensitive suffix removal algorithm. It is the most widely used of all the stemmers and implementations in many languages are available. He creates a module that exports a function which performs stemming by means of the Porter stemming algorithm. Quoting Martin Porter himself:
The Porter stemming algorithm (or ‘Porter stemmer’) is a process for removing the commoner morphological and inflexional endings from words in English. Its main use is as part of a term normalisation process that is usually done when setting up Information Retrieval systems.
Applicability of Porter Stemmer Algorithm in Our System
In our online bookshop system we analyze our customer comment, for this we need to process natural language. In this case for many grammatical reasons, comments are going to use different forms of a word, such as organize, organizes, and organizing. For this we need to stem words ( i.e positive and negative words, according to our objective).
Stemming is the process of conflating the variant forms of a word into a common representation, the stem. Here we represent some of the Examples of NL (comment) which we process using Porter Stemming algorithm.
Examples of positive / negative word in a comment and the results of stemming according to the algorithm-
Case 1:
Comment:
“This book helps me a lot”
Word “helps” that changes after stemming is “ help” according to the step 1a) in the algorithm.
Case 2:
Comment:
“It seems to be a very interesting book”
Word “interesting” that changes after stemming is “ interest” according to the step 1b) in the algorithm.
Comment
“I am failed to understand the theory of chapter four because it is not clearly written.”
Word “failed” that changes after stemming is “ fail” according to the step 1b) in the algorithm.
Case 3:
Comment:
“This book helps to improve our frequent stream of thought to achieve stillness.”
Word “stillness” that changes after stemming is “ still” according to the step 3 in the algorithm.
Case 4:
Comment:
“Limitation of explanation makes a book’s topics difficult to understand”
Word “Limitation” that changes after stemming is “ Limit” according to the step 4 in the algorithm.
Comment:
“The main attraction of the book is easy to understand its language”
Word “attraction” that changes after stemming is “attract” according to the step 4 in the algorithm.
Comment:
“This book is really helpful for young generation”
Word “helpful” that changes after stemming is “help” according to the step 3 in the algorithm.
Modification of the Algorithm
We need to fetch only positive/negative words correctly, that’s why we have to remove only step 5(a)
For this we can get some positive and negative words as correctly. As for example-
Hope, love, peace, nice, like etc which ends with “e” wouldn’t change. Likely, hopeful, nicely, lovely changes into hope, nice, love etc.
We want to change some other option in future.
Algorithm Implementation
We use C# to implement the algorithm. A simple form is designed to show the output of the stem word corresponding to our input word. We constructed a class to implement the algorithm (which is given in Appendix B). Implemented code is very simple and straightforward. Only one word can be stemmed at a time, First we convert the upper case input to the lower case, then check for the number of vowels and consonants occurring continuously and which gives m value. And after that step by step methods are run to check the conditions of the algorithm.
Limitations of Porter Stemming Algorithm
- The Porter stemming algorithm has a few parts that work better with American English than British English, so some British spellings will not be stemmed correctly. It is also definitely, English-specific, and non-English content will not be stemmed correctly.
- The Porter stemming algorithm attempts to reduce words to their lingustic root words — it does not do general substring matching. So, for instance, it should make “walk”, “walking”, “walked”, and “walks” all match in searching, but it will not make “walking” a match for “king”.
- The algorithm is careful not to remove a suffix when the stem is too short, the length of the stem being given by its measure, m. There is no linguistic basis for this approach.
Implementation of Text Mining Tools
Primary Technique
In sentiment classification, sentiment words are more important e.g. great, excellent, bad, worst. Here one thing should be in our mind that sentiment analysis is useful, but it does not say whether customer liked or disliked. A negative sentiment on an object does not mean that the reviewer does not like anything about the object. Even a positive sentiment on an object does not mean that the customer likes everything.
Since the number of reviews for an object can be large we want to produce a simple summary of opinions. The summarized opinion can be easily visualized and compared.
So our primary task is about identifying and extracting the sentiment positive and negative words from the customer’s comment.
To classify customer sentiment, our first approach is to detect positive and negative words from customer’s comment. For that we create a database that contains such positive and negative words. We match each and every word of the overall comment with those words. The frequency of the positive and negative words within the comment stands for whether the sentiment expressed by the customer is positive, negative or (possibly) neutral.
Conclusion
By the grace of Almighty Allah ,we have come to the end of our thesis report .It is not a short time work. It took us a year to complete. Our group members worked hard to make an efficient thesis.
We work to build a online book shop, designing and storing sample information in a database of our creation .We designed ER models, Relational Models ,normalized tables of the relational model and then implement the SQL Server Diagram, filled the tables with data values and queried different useful information from the database.
After the DB part we design an online bookshop in ASP.net framework .We design User Manual and Administration Manual.We tried to analyze customer sentiments based on their given comments on books. In fact we made a text mining tool. It works well in simple conditions.
We hope our tool will have an important impact in decision making for both customers and the owner of an online bookshop. Our tool has some limitations but we hope to develop it in greater depths in future.
Future work
Customer satisfaction analysis (opinion mining) based on customer reviews using text mining technique is a huge process. The opinion mining is often associated with another research topic – information retrieval (IR). Nevertheless, opinion mining proves to be a very difficult task. Text mining is a branch of data mining technique. As we are new to data mining technique we try our best to do well in our position. We want to implement a full functional tool for customer opinion analysis and want to produce the best output, as we desire. We want to show upto best 10 books in weekly basis according to our customer satisfaction. Some of the parts we implement successfully, but in future, we want to upgrade our tasks as follows-
Task 1: Modify the algorithm we use. Because in some cases it does not work properly. Means, Porter stemming algorithm stems word but in some cases the actual format of the word, which we need, is changed, which is a problem we faced. For example-
The word “excellent” in a comment is changes into the word “excel”.
So for this we will try to overcome such problems and we will modify the algorithm as much as possible.
Task 2: We integrate the modified algorithm into our solution.
Task 3: Atlast we assess the performance as a run time application.