Background and Motivation
An image retrieval system is a computer system for browsing, searching and retrieving images from a large database of digital images. Most traditional and common methods of image retrieval utilize some method of adding metadata such as captioning, keywords, or descriptions to the images so that retrieval can be performed over the annotation words.
Fuzzy logic is basically a multi-valued logic that allows intermediate values to be defined between conventional evaluations like yes/no, true/false, black/white, etc. Notions like rather warm or pretty cold can be formulated mathematically and algorithmically processed. In this way an attempt is made to apply a more human-like way of thinking in the programming of computers. Fuzzy color histogram is widely used in image retrieval system.
Numerous methods about efficient image indexing and retrieval from image are often employed to search relevant images based on the databases have been proposed for the applications such as digital library. Low-level visual features such as color, texture, and shape query image. Among these features, color constitutes a powerful visual cue and is one of the most salient and commonly used features in color retrieval systems.
Due to the development of computer networks and the low cost of large storage device, visual information has been widely used in many fields. How to retrieve the visual information efficiently has led to the rise of interest in techniques for retrieving images through image databases. Image Retrieval (IR) aims to retrieve similar or relevant images to the query image by means of image features or the keywords related with the query image. In the past, various approaches to image retrieval were proposed, most of which were Content- Based Image Retrieval (CBIR) that derives image features such as color, texture and shape or any combination of these. Some key issues involved in CBIR are as follows:
A. Semantic gap between the high-level semantic and the low-level features of an image
Human prefer to retrieve images according to the “semantic” or “concept” of an image. However, CBIR depends on the absolute distance of image features to retrieve similar images. Research has concealed that there exists a nonlinear relation between the high-level semantics and the low-level features. For instance, an image may be regarded as a similar (semantic) image although its’ color and shape (low-level features) are not quite similar to the query image.
B. Integration of various features
Multi features outperform the single feature in image retrieval. Currently, most of the weight assignment of various features is conducted in a linear way according to the users’ experience. For example, if a user thinks that color is twice important as shape, he assigns 2/3 to the color weight and 1/3 the shape weight. Such precise and fixed assignment of weights fails to reflect what human think. An efficient method to solve this problem is the famous User Relevance Feedback (URF). The deficiency of URF is that it imposes a heavy burden on user in retrieval.
C. The users’ subjective intentions
Different user may have different perception of same images, which refers to the subjectivity of users’ perceptions. The research of how to reflect it in image retrieval is rather few.
The property of the image retrieval requires the computer to retrieve images as what human thinking and not depend on the rigid distance metrics to decide the image similarity. Fuzzy logic is a powerful tool to realize this goal. Fuzzy logic has been widely used in image retrieval. Most researches adopt the fuzzy set to describe the properties of image features such as the coarse of textures, the shape size of the human’s face and the thickness of edges. Different from the previous works, we emphasis on the followings:
(1) adopting the fuzzy language variables to describe the similarity degree of image features, not the features themselves so as to infer the image similarity as human thinking;
(2) making use of the fuzzy inference to instruct the weight assignments among various image features;
(3) expressing the subjectivity of human perceptions by the fuzzy rules impliedly. Experimentally, we realize a fuzzy logic- based image retrieval system with good retrieval performance.
Objective
The objective of retrieval is to return a list of images containing the query regions. The objective is efficient retrieval of images large databases based on the color and shapes used in the images. With the increasing popularity of the use of large volume image databases in various applications, it becomes imperative to build an automatic and efficient retrieval systems to browse through the entire database. Techniques using textual attributes for annotation are limited in their applications. Our approach relies on image features that exploit visual cues such as color and shape.
Our system
Color is one of the most salient and commonly used features in image retrieval. There are three major types of color feature representations: color moments, color histogram and color sets. Among these, the color histogram is the most popular for its’ effectiveness and efficiency. However, the color histogram is liable to lose spatial information and therefore fails to distinguish images with same color but different color distributions. Many researchers had investigated this problem by integrating spatial information into the conventional histogram. Pass and Zabih divide the whole histogram into region histogram by means of color clustering. Colombo et al. propose a concept called color coherence vector (CCV) to split histogram into two parts: the coherent one and the non-coherent one depending on the sizes of their connected components. Combining color with texture, shape and direction, this method escapes comparing color of different regions. Cinque et al. present a spatial- chromatic histogram considering the position and variances of the color blocks in image. Rick Rickman and John Stonham define the color tuple histogram. They use a predefined equilateral triangle of a fixed length and then randomly move the triangle on an image to calculate the frequency of each tuple of triple pixels. Hsu et al. modify the color histogram by first selecting a set of representative colors and then analyzing the spatial information of the selected colors using maximum entropy quantization with event covering method. All the above methods attempt to improve the retrieval performance by integrating spatial information into histogram. However, the way of extracting colors from the image spoils the robustness to rotation and translation of the conventional histogram inevitably as seen with the partition of regions used by Pass and Zabih, the color block position parameter used by Cinque et al. and the shape and size of the predefined triangle used by Rick Rickman and John Stonham. Therefore these improvement methods spoil the merit of the conventional histogram. For the images with same color but different color distributions, we notice that the pixels of each color usually form several disconnected regions of different sizes, which can be used as a key to distinguish the images.
In this paper, we present a novel histogram called the Average Area Histogram (AAH) based on the area features of the regions by the pixels of each color.
Thesis Organization
In chapter 1, containing a berif discussion on the background and motivation of image retrieval system and fuzzy logic. It also contains the objective of the system and a short description of our system.
In chapter 2, containing image basics and representation model. There is short description of image processing and how image is represented by different by different color models.
In chapter 3, containing a short description on image retrieval system and different image retrieval methods such as text-based image retrieval method, content based image retrieval method etc.
In chapter 4, containing the fuzzy based image retrieval system which is consisted of four stages such as: feature extraction, fuzzifier, fuzzy inference and defuzzifier.
In chapter 5, containing the results and discussions of the fuzzy-based image retrieval system with data normalizations, fuzzy inference of Image similarity in associate with the tables and figures.
In chapter 6, containing the conclusion of the fuzzy based image retrieving system. The final summary, limitations and future works are presented in the chapter 6.
Imaging Basics and Representation Models
A digital image is an array of real or complex numbers represented by a finite number of elements. These elements are referred to as picture elements, image elements, pels, and pixels. Pixel is used to denote the elements of a digital image.
Image processing is a method to convert an image into digital form and perform some operations on it, in order to get an enhanced image or to extract some useful information from it. It is a type of signal dispensation in which input is image, like video frame or photograph and output may be image or characteristics associated with that image. Usually Image Processing system includes treating images as two dimensional signals while applying already set signal processing methods to them.
It is among rapidly growing technologies today, with its applications in various aspects of a business. Image Processing forms core research area within engineering and computer science disciplines too.
Image processing basically includes the following three steps.
Importing the image with optical scanner or by digital photography.
Analyzing and manipulating the image which includes data compression and image enhancement and spotting patterns that are not to human eyes like satellite photographs.
Output is the last stage in which result can be altered image or report that is based on image analysis.
Purpose of Image processing
The purpose of image processing is divided into 5 groups. They are:
1. Visualization – Observe the objects that are not visible.
2. Image sharpening and restoration – To create a better image.
3. Image retrieval – Seek for the image of interest.
4. Measurement of pattern – Measures various objects in an image.
5. Image Recognition – Distinguish the objects in an image.
We can represent digital images by different types of color models:
The RGB Model
In the RGB model, an image consists of three independent image planes, one in each of the primary colors: red, green and blue. (The standard wavelengths for the three primaries are as shown in figure 2.1). Specifying a particular color is by specifying the amount of each of the primary components present. Figure 2.2 shows the geometry of the RGB color model for specifying colors’ using a Cartesian coordinate system. The grayscale spectrum, i.e. those colors made from equal amounts of each primary, lies on the line joining the black and white vertices.
This is an additive model, i.e. the colors present in the light add to form new colors, and is appropriate for the mixing of colored light for example.
The HSV Model
The HSV stands for the Hue, Saturation, and Value based on the artists (Tint, Shade, and Tone). The coordinate system in a hexagon in Figure 2.3(a). and Figure 2.3(b) A view of the HSV color model. The Value represents intensity of a color, which is decoupled from the color information in the represented image. The hue and saturation components are intimately related to the way human eye perceives color resulting in image processing algorithms with physiological basis.
As hue varies from 0 to 1.0, the corresponding colors vary from red, through yellow, green, cyan, blue, and magenta, back to red, so that there are actually red values both at 0 and 1.0. As saturation varies from 0 to 1.0, the corresponding colors (hues) vary from unsaturated (shades of gray) to fully saturated (no white component). As value, or brightness, varies from 0 to 1.0, the corresponding colors become increasingly brighter.
The HSI Model
As mentioned above, color may be specified by the three quantities hue, saturation and intensity. This is the HSI model, and the entire space of coolers that may be specified in this way.
Colors on the surface of the solid are fully saturated, i.e. pure colors, and the grayscale spectrum is on the axis of the solid. For these colors, hue is undefined.
Conversion between the RGB model and the HSI model is quite complicated. The intensity is given by:
Where the quantities R, G and B are the amounts of the red, green and blue components, normalized to the range [0, 1]. The intensity is therefore just the average of the red, green and blue components. The saturation is given by:
S = 1- = 1-
Where the min(R, G, B) term is really just indicating the amount of white present. If any of R, G or B is zero, there is no white and we have a pure color.
The YIQ Model
The YIQ (luminance-in phase-quadrature) model is a recording of RGB for color television, and is a very important model for color image processing. The conversion from RGB to YIQ is given by:
|
The luminance (Y) component contains all the information required for black and white television, and captures our perception of the relative brightness of particular colors. That we perceive green as much lighter than red, and red lighter than blue, is indicated by their respective weights of 0.587, 0.299 and 0.114 in the first row of the conversion matrix above. These weights should be used when converting a color image to grayscale if you want the perception of brightness to remain the same.
The Y component is the same as the CIE primary Y.
Image (a) shows a color test pattern, consisting of horizontal stripes of black, blue, green, cyan, red, magenta and yellow, a color ramp with constant intensity, maximal saturation, and hue changing linearly from red through green to blue, and a grayscale ramp from black to white. Image (b) shows the intensity for image (a). Note how much detail is lost. Image (c) shows the luminance. This third image accurately reflects the brightness variations perceived in the original image
The CMY Model
The CMY (cyan-magenta-yellow) model is a subtractive model appropriate to absorption of colors, for example due to pigments in paints. Whereas the RGB model asks what is added to black to get a particular color, the CMY model asks what is subtracted from white. In this case, the primaries are cyan, magenta and yellow, with red, green and blue as secondary colors.
When a surface coated with cyan pigment is illuminated by white light, no red light is reflected, and similarly for magenta and green, and yellow and blue. The relationship between the RGB and CMY models is given by:
| æ ç ç ç ç è |
| ö ÷ ÷ ÷ ÷ ø | = | æ ç ç ç ç è |
|
The CMY model is used by printing devices and filters.
The figure on the left shows the additive mixing of red, green and blue primaries to form the three secondary colors yellow (red + green), cyan (blue + green) and magenta (red + blue), and white ((red + green + blue). The figure on the right shows the three subtractive primaries and their pair wise combinations to form red, green and blue, and finally black by subtracting all three primaries from white.
Image Retrieval Method
Image Retrieval
“An image retrieval system is a computer system for browsing, searching and retrieving images from a large database of digital images.”
Most traditional and common methods of image retrieval utilize some method of adding metadata such as captioning, keywords, or descriptions to the images so that retrieval can be performed over the annotation words. Manual image annotation is time-consuming, laborious and expensive, to address this, there has been a large amount of research done on automatic image annotation.
At the present time, there are many techniques available for image retrieval. The image retrieval based on image content is more desirable in a number of applications. Traditionally, textual features such as filenames, caption and keywords have been used to annotate and retrieve images. But, there are several problems. Such as, human intervention is required. Further, it needs to express the spatial relationships among the various objects in an image to understand its content. Moreover, the use of keywords becomes not only complex, but also inadequate to represent the image content.
As a result, it needs to automatically extract primitive visual features from the images and to retrieve images on the basis of these features. Humans use color, shape, and texture to understand and recollect the contents of an image. Recent years have seen a rapid increase in the size of digital image collections. Everyday, both military and civilian equipment generates giga-bytes of images. A huge amount of information is out there. However, we cannot access or make use of the information unless it is organized so as to allow efficient browsing, searching, and retrieval. Image retrieval has been a very active research area since the 1970s, with the thrust from two major research communities, database management and computer vision. These two research communities study image retrieval from different angles, one is text-based and the other content-based.
Text-Based Image Retrieval
The text-based image retrieval can be traced back to the late 1970s. This approach interpret image manually with text labels and attributes such as filenames, captions, and keywords. These textual descriptions try to describe the contents of images. However, it has insuperable problems. First of all, human intervention is required to describe and tag the contents of the images in terms of a selected set of captions and keywords. In most of the images there are several objects that could be referenced, each having its own set of attributes. Further, we need to express the spatial relationships among the various objects in an image to understand its content. As the size of the image databases grow, the use of keywords becomes not only cumbersome but also inadequate to represent the image content. The keywords are inherently subjective and not unique. Often, the reselected keywords in a given application are context dependent and do not allow for any unanticipated search. If the image database is to be shared globally then linguistic barriers will render the use of keywords ineffective. Another problem with this approach is the inadequacy of uniform textual descriptions of such attributes as color, shape, texture, layout, and sketch. The other difficulty is the subjectivity of human perception. That is, for the same image content different people may perceive it differently. The perception subjectivity and annotation impreciseness may cause unrecoverable mismatches in retrieval processes.
Content-Based Image Retrieval
In the early 1990s, because of the emergence of large-scale image collections, the two difficulties faced by the manual annotation approach became more and more acute. To overcome these difficulties, content-based image retrieval (CBIR) was proposed. That is, instead of manual annotations by text-based key words, images would be indexed by their own visual and semantic content, such as color and texture. Since then, many techniques in this research direction have been developed and many image retrieval systems have been built. The advances in this research direction are mainly contributed by the computer vision community. This 22 approach has established a general framework of image retrieval from a new perspective. There are three fundamental bases for content-based image retrieval, i.e. visual feature extraction, multidimensional indexing, and retrieval system design. CBIR technique is however more challenging to investigate and implement, because it is not obvious how to extract relevant content from images, which would in addition be suitable for searching and retrieval. Some feature extraction techniques for CBIR are discussed in the following sections.
Feature Extraction Techniques on Color
Recently there has been an increased concentration in color research in image retrieval and object recognition. Swain and Ballard (1991) have proposed a color matching method called histogram intersection in their paper on “color indexing”. There are also two new methods such as the Distance Method and the Reference Color Method are used to retrieve images.
Histogram Intersection
Let IR, IG, and IB be the normalized color histograms of stored image I (an image in the in the database) and let QR, QG, QB be the normalized color histograms of the query image Q, each containing r, g and b bins respectively. The similarity between the query image (Q) and a stored image (I) in the database, S(I,Q) is given by the following equation:
The value of S(I,Q) lies in the interval. The main advantage of the use of color histograms is that they are rotation and translation invariant for a constant background. The match value is computed for every stored image’s histogram and the value is closer to unity if the model image is similar to the query image. If the histograms I and Q are identical then S(I,Q) =1 . However the histogram intersection method sometimes produces incorrect results and introduces noise.
The Distance Method
Euclidean distance is used as a metric to compute the distance between the feature vectors. Let IR, IG, and IB the normalized color histograms of an image in the database, and let QR,, QG, and QB be the normalized color histograms of the query image. The similarity between the query image and a stored image in the database, S (I,Q) , is given by the following equation:
S(I,Q)=1.0-
……..(3.2)
The value of S (I,Q) lies in the interval [0, 1]. If images I and Q are identical then S (I,Q) = 1 . Although the distance method computes a coarse feature measure and use a relative distance measure for a given pair of images, it involves less computation and gives fast and plausibly accurate results.
The Reference Color Table Method
The Reference color table method can be considered as an intermediate approach to the distance method and histogram intersection approaches, which reduces the detail of histogram matching yet retains the speed and robustness of the distance method. 24 In the Reference color table method, we define a set (table) of reference colors.
This set of colors is selected such that all the colors in the database are approximately covered perceptually. So, for this method,
= (ϒ1,ϒ2,ϒ3… … …ϒn) (3.3)
where λi is the relative pixel frequency (with respect to the total number of pixels) for the ith reference table color in the image. The size of the reference color table is n.
For computing the similarity, we have to calculate the weighted distance using the following equation:
D = …………………………………..(3.4)
Where and are the color features of the query image and database image respectively.
The reference table method is the best in terms of retrieval efficiency. But, the drawback of this method is that it requires a pre-defined set of reference feature (color, in particular) which can approximately cover all features (colors) in the selected application. The reference feature or color table method requires a representative sample of all images stored in the database in order to select the reference feature or color table. Such a priori knowledge is impossible to obtain in many applications e.g. trademarks database.
Feature Extraction Techniques on Shape
Usually shape description and recognition techniques are classified as Region or Boundary based techniques. Region based techniques take into account internal details and boundary details. On the other hand, the boundary-based techniques use only the contour or border of an object. Techniques of both classes can be classified into spatial and transform domains, the spatial domains techniques 25 measure the appearance of the objects. They are used when description is made from the area of the object inside its boundary. For the transform domains techniques, they are based on mathematical transforms such as Fourier and Wavelet transforms.
Region-Based Geometric Techniques
Region based techniques apply mathematical properties derived from the objects such as moment invariants, rectangularity, roundness/circularity etc. They take consideration on the interior details within complete contour of the objects. The calculations of this kind of techniques are usually performed for binary images.
Boundary-Based Geometric Techniques
Boundary-based geometric techniques are derived from the boundaries of the objects such as histogram of edge directions, boundary moment invariants etc.
High Dimensional Indexing
To make the content-based image retrieval truly scalable to large size image collections, efficient multidimensional indexing techniques need to be explored. There are two main challenges in such an exploration for image retrieval:
High dimensionality. The dimensionality of the feature vectors is normally of the order of 102
Non-Euclidean similarity measure. Since Euclidean measure may not effectively simulate human perception of a certain visual content, various other similarity measures, such as histogram intersection, cosine, correlation, need to be supported. 26
Towards solving these problems, one promising approach is to first perform dimension reduction and then to use appropriate multidimensional indexing techniques, which are capable of supporting non-Euclidean similarity measures.
Dimension Reduction
Even though the dimension of the feature vectors in image retrieval is normally very high, the embedded dimension is much lower. Before we utilize any indexing technique, it is beneficial to first perform dimension reduction. At least two approaches have appeared in the literature, i.e. Karhunen–Loeve transform (KLT) and column-wise clustering. KLT and its variation in face recognition, eigen image, and its variation in information analysis, principal component analysis (PCA), have been studied by researchers in performing dimension reduction. Considering that the image retrieval system is a dynamic system and new images are continuously added to the image collection, a dynamic update of indexing structure is indispensably needed. This algorithm provides such a tool. In addition to KLT, clustering is another powerful tool in performing dimension reduction. The clustering technique is used in various disciplines such as pattern recognition, speech analysis, information retrieval, and so on. Normally it is used to cluster similar objects (patterns, signals, and documents) together to perform recognition or grouping. This type of clustering is called row-wise clustering. However, clustering can also be used column-wise to reduce the dimensionality of the feature space.
One thing worth pointing out is that blind dimension reduction can be dangerous, since information can be lost if the reduction is below the embedded dimension. To avoid blind dimension reduction, a post verification stage is needed.
Multidimensional Indexing Techniques
After we identify the embedded dimension of the feature vectors, we need to select appropriate multidimensional indexing algorithms to index the reduced but still high dimensional feature vectors. There are three major research communities contributing in this area, i.e. computational geometry, database management, and pattern recognition. The existing popular multidimensional indexing techniques include the bucketing algorithm, k-d tree, priority k-d tree, quad-tree, K-D-B tree, hB-tree, R-tree and its variants R|+|-tree and R|*|-tree. In addition to the above approaches, clustering and neural nets, widely used in pattern recognition, are also promising indexing techniques.
After dimension reduction using the Eigen image approach, the following three characteristics of the dimension-reduced data can be used to select good existing
Indexing algorithms:
The new dimension components are ranked by decreasing variance,
The dynamic ranges of the dimensions are known,
The dimensionality is still fairly high.
So far, the above approaches only concentrated on how to identify and improve indexing techniques which are scalable to high dimensional feature vectors in image retrieval. The other nature of feature vectors in image retrieval, i.e. non-Euclidean similarity measures, has not been deeply explored. The similarity measures used in image retrieval may be non-Euclidean and may even be non-metric. There are two promising techniques towards solving this problem, i.e. clustering and neural nets.
Image Retrieval Systems
Content-based image retrieval has become a very active research area, since the early 1990s. Many image retrieval systems have been built for commercial as well as research purpose. Most image retrieval systems support one or more of the following options:
• Random browsing
• Search by example
• Search by sketch
• Search by text (including key word or speech)
• Navigation with customized image categories.
We have seen the provision of a rich set of search options today, but systematic Studies involving actual users in practical applications still need to be done to explore the trade-offs among the different options mentioned above. Recently, attempts have been made to develop general purpose image retrieval systems based on multiple features that describe the image content. These systems attempt to combine shape, color, and texture cues for a more accurate retrieval. Here, we will select a few representative systems and highlight their distinct characteristics.
QBIC
QBIC (Query By Image Content) is the first commercial content-based image retrieval system. Its system framework and techniques have profound effects on later image retrieval systems. This system allows users to search through large online image databases using queries based on sketches, layout or structural descriptions, texture, color, and sample images. Therefore, QBIC techniques serve as a database filter and reduce the search complexity for the user. These techniques limit the content-based features to those parameters that can be easily extracted, such as color distribution, texture, shape of a region or an object, and layout. The color feature used in QBIC are the average (R, G, B), (Y, i, q), (L, a, b), and MTM (mathematical transform to Munsell) coordinates, and a k-element color histogram. Its texture feature is an improved version of the Tamura texture representation; i.e. combinations of coarseness, contrast, and directionality. Its shape feature consists of shape area, circularity, eccentricity, major axis orientation, and a set of algebraic moment invariants. QBIC is one of the few systems, which takes into account the high dimensional feature indexing. The 29 system offers a user a virtually unlimited set of unanticipated queries, thus allowing for general purpose applications rather than catering to a particular application. Color- and texture-based queries are allowed for both images and objects, whereas shape-based queries are allowed only for individual objects and layout-based queries are allowed only for an entire image. Although user can use multiple cues as a query, one needs to be well trained before QBIC system effectively.
ARTISAN
The development of the ARTISAN (Automatic Retrieval of Trademark Images by Shape Analysis) aims at providing a prototype of shape retrieval for trademark images. The approach is firstly to extract region boundaries of a shape and represented them by straight-line and circular-arc approximately. Then the shape features of aspect ratio, roundness, relative area, directedness, straightness, etc. are extracted and stored into the database. ARTISAN was experimented with more than 10000 trademark images.
Virage
Virage is a content-based image search engine developed at Virage Inc. Similar to QBIC, Virage supports visual queries based on color, composition (color layout), texture, and structure (object boundary information). But Virage goes one step further than QBIC. It also supports arbitrary combinations of the above four atomic queries. The users can adjust the weights associated with the atomic features according to their own emphasis.
Retrieval Ware
RetrievalWare is a content-based image retrieval engine developed by Excalibur Technologies Corp. Its earlier publications were based on neural nets. Its more recent search engine uses color, shape, texture, brightness, color layout, and aspect 30 ratio of the image, as the query features. It also supports the combinations of these features and allows the users to adjust the weights associated with each feature.
Photobook
Photobook is a set of interactive tools for browsing and searching images developed at the MIT Media Lab. It is a set of interactive tools for browsing and searching an image database. The features used for querying can be based on both text annotations and image content. The key idea behind the system is semantics-preserving image compression, which reduces images to a small set of perceptually significant coefficients. These features describe the shape and texture of the images in the database. Photobook uses multiple image features for querying general purpose image databases. It consists of three subbooks from which shape, texture, and face features are extracted, respectively. Users can then query, based on the corresponding features in each of the three subbooks.
STAR
STAR (System for Trademark Archival and Retrieval) system uses features based on R, G, and B color components, invariant moments, and Fourier descriptors extracted from manually isolated objects. The features used to describe both the color and shape in an image are non-information preserving or ambiguous in nature and hence they cannot be used to reconstruct the image. However, they are useful as approximate indicators of shape and color.
VisualSEEk and WebSEEk
VisualSEEk is a visual feature search engine and WebSEEk is a World Wide Web oriented text/image search engine, both of which are developed at ColumbiaUniversity. Main research features are spatial relationship query of image regions and visual feature extraction from compressed domain. The visual features used in 31 their systems are color set and wavelet transform based texture feature. To speed up the retrieval process, they also developed binary tree based indexing algorithms. VisualSEEk supports queries based on both visual features and their spatial relation-ships. This enables a user to submit a “sunset” query as red-orange color region on top and blue or green region at the bottom as its “sketch.”
WebSEEk is a web oriented search engine. It consists of three main modules, i.e. image/video collecting module, subject classification and indexing module, and search, browse, and retrieval module. It supports queries based on both keywords and visual content.
Netra
Netra is a prototype image retrieval system developed in the UCSB Alexandria Digital Library (ADL) project. Netra uses color, texture, shape, and spatial location information in the segmented image regions to search and retrieve similar regions from the database. Main research features of the Netra system are its Gabor filter based texture analysis, neural net-based image thesaurus construction and edge flow-based region segmentation.
MARS
MARS (Multimedia Analysis and Retrieval System) was developed at University of Illinois at Urbana-Champaign. MARS differs from other systems in both the research scope and the techniques used. It is an interdisciplinary research effort involving multiple research communities: computer vision, database management system (DBMS), and information retrieval (IR). The research features of MARS are the integration of DBMS and IR (exact match with ranked retrieval), integration of indexing and retrieval (how the retrieval algorithm can take advantage of the underline indexing structure), and integration of computer and human. The main focus of MARS is not on finding a single “best” feature representation, but rather on how to organize various visual features into a meaningful retrieval architecture which can dynamically adapt to different applications and different users. MARS formally proposes relevance feedback 32 architecture in image retrieval and integrates such a technique at various levels during retrieval, including query vector refinement, automatic matching tool selection, and automatic feature adaption.
Learning-Based System
A general purpose image database system should be able to automatically decide on the image features that are useful for retrieval purposes Minka and Picard describe an interactive learning system using a society of models. Instead of requiring universal similarity measures or manual selection of relevant features, this approach provides a learning algorithm for selecting and combining groupings of the data, where these groupings are generated by highly specialized and context-dependent features. The selection process is guided by a rich user interaction where the user generates both positive and negative retrieval examples.
A greedy strategy is used to select a combination of existing groupings from the set of all possible groupings. These modified groupings are generated based on the user interactions, which over a period of time; replace the initial groupings that have very low weights. Thus, the system performance improves with time through user interaction and feedback.
Other Systems
ART MUSEUM, developed in 1992, is one of the earliest content-based image retrieval systems. It uses the edge feature as the visual feature for retrieval. Blob-world, developed at UC-Berkeley, provides a transformation from the raw pixel data to a small set of localized coherent regions in color and texture space. This system allow the user to view the internal representation of the submitted image and the query results and therein enables the user to know why some “no similar” images are returned and can therefore modify his or her query accordingly. The distinct feature of CAETIIML, built at PrincetonUniversity, is its combination of the on-line similarity searching and off-line subject searching.
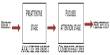
Fuzzy Based Image Retrieval System
The fuzzy logic-based image retrieval system is composed of the following four parts illustrated in figure 3.1.
A. Feature Extraction
The color feature C is represented by the histogram in HSV-space. We adopt the traditional moment invariants to extract the shape feature S .
B. Fuzzifier
Suppose query image is Q and images from the database is I .
The color distance Dc (Cq , C i ) and shape distance Ds (S q , S i )between image Q and I are two inputs of the fuzzy logic-based image retrieval system. Three fuzzy variables including “very similar”, “similar” and “not similar” are used to describe the feature difference Dc and Ds. By such descriptions, we can infer the similarity of images in the same way as what human think.
C. Fuzzy Inference
According to the general knowledge of an object and the users’ retrieval requirements, a fuzzy rule base including nine rules is created.
D. Defuzzifier
Output of the fuzzy system Sim is the similarity of two images and it is also described by three fuzzy variables including “very similar”, “similar” and “not similar”. We adopt the Center Of Gravity (COG) method to defuzzify the output.
E. FEATURE EXTRACTION
The color and shape representations and measurement methods are introduced in the following sections.
COLOR FEATURE DESCRIPTION
Given a color space C , the conventional histogram H of image I is defined as follow:
H c(I) ={N(Ii, Ci)│I €[1,…..,n]}… … …(1)
Where N ( I , C ) is the number of pixels of I fall into cell Ci in the color space C and i is the gray level.Hc (I ) shows the proportion of pixels of each color within the image. The color difference Dc (Cq , C i ) is the histogram distance defined by Eq. (2) as follows:
Dc (Cq , C i ) = d(H(I),H(Q))= … … …(2)
Swain and Ballard [8] define a distance measure method called histogram intersection:
Dc (Cq , C i ) = d(H(I),H(Q))= … … …(3)
See the above distance measure methods, they only make use of the total amount of the pixels with color to compare two histograms, not consider the different spatial distribution for color i in image I. See Eq. (2) and Eq. (3), the default coefficient of ( ) H(Ii) and H (Qi )is 1, which means that the difference between the two histograms is just determined by the total number of pixels of each color. Actually, within each color bin, there exists a spatial difference. To solve this problem, we present a novel histogram called Average Area Histogram (AAH). In the AAH, we integrate the area feature of the regions formed by each color into the conventional histogram. Let D be the number of disconnected regions formed by the pixels with color i of image I in the color space C. Here we ignore the regions with only 1 pixel for they have no effect on the retrieval performance.
D(I,Ci) = {N(C8i)│iЄ[1,……n]}… … …(4)
Where N(C8i)│counts the number of disconnected regions formed by the pixels with color i through an 8-connectivity operation on image I . Then the average area histogram H * can be defined as follow:
H *(Ci) = {N(I, Ci)/D((I, Ci) │iЄ[1,….n]}… … …(5)
Where N(Ii,Ci) counts the total number of pixels with color i in the image I , which can also be regarded as the area value of the regions formed by the pixels with color i. H then represents the average area value of these regions for color i.
Fig.4.2 illustrates three common cases where the pixels of color i form the connected and disconnected regions. For the three cases, suppose that the sum of these pixels is equal or close. The AAH can distinguish the three cases (A), (B) and (C) correctly.
However, the conventional histogram method only considers the total amount of color i that is the sum of the areas of all the disconnected regions. Consequently, these three cases will be regarded as identical and thus be mismatched. In fact, the conventional histogram is only effective for case A. In most mismatching cases of the traditional histogram, it cannot distinguish the case (a) from case (b) while the AAH outperforms the traditional histogram to distinguish (a) from (b) and (a) from (c). Fig.4 shows the comparison of the traditional histogram and the AAH of image A and B illustrated.
In Fig.4.3 In Fig.4.3, (1) and (2) are the conventional histograms of the image (a) and (b) respectively, (3)
And (4) are the AAH of them. Evidently, the AAH of image A and B is more dissimilar compared with their traditional histograms, which is consistent with the different contents in the image (a) and (b). In other words, the AAH is more suitable to reflect the real color distributions in the image than the traditional histogram.
SHAPE FEATURE DESCRIPTION
In general, shape representation can be categorized into either boundary-based or region-based. The former uses only the outer boundary characteristics of the entities while the latter uses the entire region. Well-known methods of the two types include the Fourier descriptors and the moment invariants respectively.
Results And Discussions
Fuzzy Logic-Based Image Similarity Matching
Data Normalization
See Eq. (3) in section 3, if Dc (Cq , C i ) I is close to 1, it indicates that the two images Q and I have strongly similar color. However, in the fuzzy inference, we assume that the feature distance which closes to 1 means “not similar”. So we must convert Dc (Cq , C i ) through Eq. (9):
Dc (Cq , C i ) = || Dc (Cq , C i ) -1 ||… … …(9)
To satisfy the requirement of the Membership Grade Function used in the fuzzy logic-based image retrieval system, the shape difference Ds (SQ,SI) needs to be
transformed into range [0,1] with Gaussian normalization method [18].
Ds’ = (Ds-mDs/3σDs +1)/2… … …(10)
Eq. (10) guarantees that 99 percents of D S ‘ fall into
to range [0,1] and md and σd are the mean value and standard deviation of Ds respectively.
Fuzzy Inference of Image Similarity
In general, human accept and use the following experiences to retrieve images: if the feature difference
of two images is no more than 20%, the two images are very similar, between 30%-50% similar, between 70%-90% or above not similar. The Membership Grade Function (MGF) to describe the similarity degree difference of the color and shape features is built according to the above experiences.
Next we will fuzzify the outputs and input of the system. Three fuzzy variables including “very similar”, “similar” and “not similar” are used to describe the two inputs of the system. Their respective MGFs are Gauss MGF, Union Gauss MGF and Gauss MGF. The output of the system is the similarity of images, which is also described by three same fuzzy variables. Their respective MGFs are: Gauss MGF, Union Gauss MGF and Gauss MGF. Figure 5.4 shows the MGFs of the two inputs and one output of the fuzzy logic-based image retrieval system.
Once we acquire the fuzzy descriptions of the color difference and shape difference of the two images, the rule base including 9 rules can be built to make an inference of their similarity. The fuzzy relation
Matrix R is computed in Eq. (11). The inference can be conducted by R.
R = (Dc × Ds) ×S… … … (11)
These rules are consistent with the user’s requirements and what his perceptions of an object.
The weight of a rule reflects the user’s confidence of it. For one user named A, wants to retrieve all of the flower images with different color and shape to the query image named 5.jpg as shown in the top left corner of Fig.5.6. So A assumes that two images with similar color and very similar shape may be similar.
According to A’s requirements, the fuzzy rules are shown in table 1. For another user named B, he just
Retrieves the flower images with strongly similar color to 5.jpg. So B may think that two images with similar color and very similar shape are not similar. The rules related to his requirements are shown in table 2. The differences of the two rule bases are illustrated in bold sequence number in table 1 and table 2. The two corresponding output surfaces are illustrated in Fig.5.5. Fig.5.6 shows their respective retrieval results (the top is for user A and the bottom user B). Obviously, the retrieval results satisfy the two users’ subjective intentions and initial requirements. Each rule processes one of the possible situations of the color and shape features of two images. The 9 rules altogether deal with the weight assignments impliedly in the same way as what human think. In the fuzzy logic-based image retrieval system, the fuzzy inference processes all the 9 cases in a parallel manner, which makes the decision more reasonable.
If different objects have same features variance scopes, the rule base will be similar and hence our proposed method has a good robustness to images categories. For example, for a stamp and a book images, their shape feature variance is very small for most of them are square; their color features variance is very large. Various colors are possible. Users’ perceptions of their features will be close or similar, which makes the fuzzy rules are also similar or close.
Image Preprocessing
Before experiment, the color images in RGB-space are converted into HSV-space. An image database including 500 images involved in 48 categories are used in our experiment. Their color and shape features are extracted by methods introduced in section 3 and stored in the database as the retrieval indexes. The experiments include two parts: one is for the AAH and the other for the fuzzy image retrieval.
Retrieval Performance
There are two principals to evaluate a retrieval system: the precision and the recall measures. Suppose R( q) is the set of images relevant for the query q and A( q) is the set of retrieved images. The precision of the result is the fraction of retrieved images that are truly relevant to the query:
P = … … …(12)
While the recall is the fraction of relevant images that are actually retrieved:
R = … … …(13)
To verify the efficiency of the AAH, the gray-scaled color space and the HSV color space are selected to perform the retrieval respectively. We adopt Eq. (2) as the distance metric for the gray level images and Eq. (3) for HSV-space images. Fig.5.7 and Fig.5.8 show the retrieval performance comparison of the three histograms in the two color spaces respectively. Result shows that our proposed histograms
outperform the conventional histogram. The performance improvements come from the correct matching of those images that have similar color distribution as case (B) and (C) illustrated.
When retrieve images, user specifies each rules according to the importance of the color and shape feature to the query image as shown in table 1 or 2. Of course, we can also establish a rule base related with certain types of images before retrieval and make use of them in the retrieval time. Figure 5.9 illustrates the precision-recall of our proposed fuzzy logic-based image retrieval.
The precision and recall verifies the efficiency and feasibility of applying the fuzzy method in the image retrieval. For the images with large appearance variety such as lamp, flower and knap etc., our proposed method has an average precision of above 41% vs. the top 20 images, which means that the fuzzy retrieval method has a good robustness to the image categories.
Conclusions
Summary
In this experiment, a fuzzy logic-based image retrieval system based on color and shape features is presented. For the fuzzy inference integrates various features perfectly and reflects the user’s subjective requirements, the experiments achieve good performance and demonstrate the efficiency and robustness of our scheme. If we apply this method for field-orientated image retrieval so as to embed the users’ retrieval requirements into the fuzzy rules, we have reason to believe that the image retrieval performance will be improved.
Limitations and Future Works
Our future work deals with making the system more robust and stable, as well as speedy by adding more features and including indexing technique.Currently, our system has no learning capabilities. So another future extension will be in the direction of allowing our system to learn and adjust weights through positive and negative examples of each query.
However, for large databases our technique is applicable for appreciably accurate results with a little compensation of computation time.