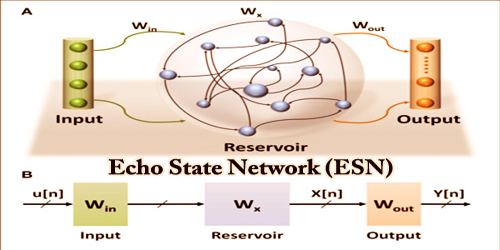
An echo state network (ESN) is a new form of recurrent neural network designed to help engineers benefit from this type of network, without any of the difficulties of training other conventional forms of recurrent neural networks. It is a recurrent neural network (with usually 1 percent connectivity) with a sparsely connected hidden layer. The connectivity of the hidden neurons and their weights are set and distributed randomly. Output neuron weights should be learned so that particular temporal patterns can be generated or replicated by the network. ESN is characterized by an outsized reservoir converting the input file to a high-dimensional dynamic state space, which may be the “echo” of recent input history.
This network’s main importance is that while its action is non-linear, the only weights that are altered during training are for the synapses that link the hidden neurons to the output neurons. In general, the echo state network (ESN) deals with a random, large, fixed recurrent neural network in which each neuron receives a non-linear response signal, and neuron connectivity and weights are fixed and randomly assigned to it. Thus, the error function is quadratic with relation to the parameter vector and might be differentiated easily to a linear system. ESN has been applied in an exceedingly wide selection of domains, like scheme identification and statistic prediction. But one of the drawbacks in ESN is its poorly understood reservoir properties. The echo state network achieves a sort of versatile form of learning by interacting with input weights this way.
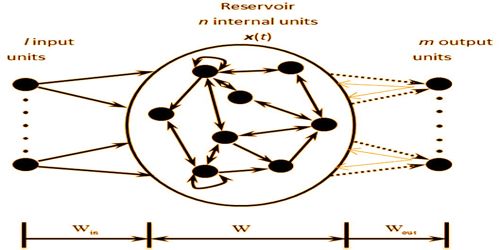
The basic structure of a standard ESN
Before practicing, the solid lines denote the randomly generated connections fixed. The dotted lines indicate the modified connections during training. The grey solid lines denote potential but not necessary feedback connections.
The basic concept of ESNs is shared with Liquid State Machines (LSM), which Wolfgang Maass developed independently of and concurrently with ESNs (Maass W., Natschlaeger T., Markram H. 2002). Alternatively, a nonparametric Bayesian formulation of the output layer can be considered, in which: I a prior distribution is placed over the output weights; and (ii) the output weights, provided the training data, are marginalized in the sense of prediction generation. This thought has been shown in by utilizing Gaussian priors, whereby a Gaussian cycle model with ESN-driven bit work is gotten. Such an answer was appeared to beat ESNs with teachable (limited) arrangements of loads in a few benchmarks.
The randomly generated values of connectivity and the weight structure of the reservoir’s internal neurons which lead to ESN’s randomness and instability in prediction efficiency. The random and unpredictable prediction, however, is not constantly seen as a drawback of the machine learning algorithm. A model of an echo state network includes three segments: an information signal, a dynamic reservoir, and an output or “teacher” signal. Specialists portray crafted by this model as “harvesting reservoir states” and processing yield loads to frame AI examination.
The ESN’s main approach is, firstly, to operate a random, large, fixed, recurrent neural network with the input signal, which induces a nonlinear response signal in each neuron within this “reservoir” network, and secondly to link the desired output signal via a trainable linear combination of all these responses. Essentially, different random states within the reservoir “echo” over time, and therefore the network gets these interesting inputs and works on them to come up with a particular “activation trajectory” then the strength of the network is its ability to generalize from these inputs with an input driving the reservoir model.
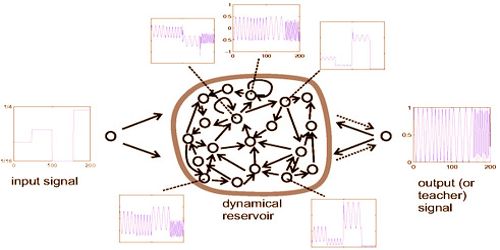
The basic schema of an ESN illustrated with a tuneable frequency generator task.
The earliest currently known formulation of the reservoir computing idea was given by L. Schomaker, who described how the desired target output from an RNN (Recurrent Neural Network) can be obtained by learning to combine signals from a randomly configured ensemble of spiking neural oscillators. Usually, recurrent neural networks (RNNs) are used for: studying complex processes: signal processing in engineering and telecommunications, vibration analysis, seismology, engine, and generator power. Signal generation and forecasting: text, music, electrical signals. Biological systems modeling, neuroscience (cognitive neurodynamics), memory modeling, Brain-Computer Interfaces (BCIs), Kalman processes and filtering, military applications, modeling of uncertainty, etc.
For ensemble learning, one of the most well known AI calculations, the irregularity and assorted variety of individual students in a gathering contribute in advancing the speculation execution of the student’s troupes. Consequently, the troupe learning strategy is acquainted with the ESN model to take care of the proposed ESN issue. Nutshell, weights are allocated randomly to the echo state network, so it is easy to practice. The functionality is in the way the network uses its inputs to deliver outcomes for learning. Another component of the ESN is the independent activity in the forecast: if the Echo State Network is prepared with info that is a back shifted adaptation of the yield, at that point, it very well may be utilized for signal age/expectation by utilizing the past yield as information.
Echo State Networks (ESNs) can actually be constructed in various ways. They can be set up with or without explicitly trainable input-to-output links, with or without feedback from output reservation, with various neurotypes, various internal communication patterns of the reservoir, etc. Moreover, the yield loads can be registered with any of the accessible disconnected or online calculations for straight relapse. Other than least-mean-square blunder arrangements (i.e., direct relapse loads), edge amplification models are known from preparing support vector machines that have been utilized to decide yield loads. The fixed RNN functions as a nonlinear, random medium whose dynamic response, the “echo” is used as the basis of the signal. This base can be trained in linear combination to recreate the desired performance by minimizing some error criteria.
Information Sources: