Sparse data, in most cases, means that there are many gaps in the data being captured. For example, in the case of the sensor indicated above, the sensor may only provide a signal when the state changes, such as when a door in a room moves. Because the door is not always moving, this information will be collected in spurts. As a result, the data is limited. However, if the sensor measures, say, wind speed, the numbers vary on a regular basis. As a result, the resulting data set is dense.
A machine-learning approach developed for sparse data predicts fault slip in laboratory earthquakes and may be useful in predicting fault slip and maybe earthquakes in the field. The research by a team from Los Alamos National Laboratory builds on past success with data-driven systems that succeeded for slow-slip events on Earth but fell short on large-scale stick-slip faults that generate very little data but huge quakes.
“Because major faults may slip only once every 50 to 100 years or longer, seismologists have had little opportunity to collect the vast amounts of observational data needed for machine learning,” said Paul Johnson, a geophysicist at Los Alamos and a co-author on a new paper, “Predicting Fault Slip via Transfer Learning,” published in Nature Communications.
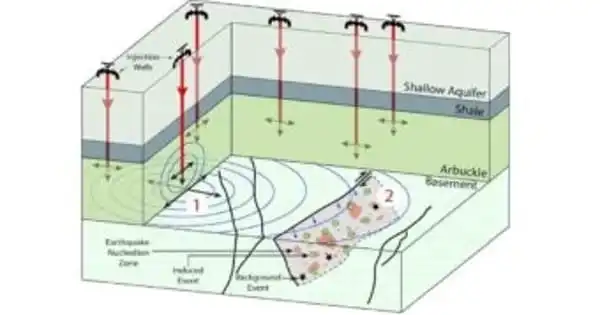
We may model a seismogenic fault in the earth, then use the same kind of cross-training to include data from the actual fault for a section of the slip cycle. The goal would be to forecast fault movement in a seismogenic fault like the San Andreas, where data is restricted due to rare earthquakes.
Paul Johnson
To compensate for the scarcity of data, the team trained a convolutional neural network on the output of numerical models of laboratory quakes as well as a tiny set of data from lab tests, according to Johnson. Then, using the remaining unobserved lab data, scientists were able to forecast fault slippage.
According to Johnson, this was the first use of transfer learning to numerical models for predicting fault slide in lab tests, and no one had before applied it to earth observations.
Transfer learning allows researchers to generalize from one model to another in order to overcome data sparsity. The method enables the laboratory team to expand on their previous data-driven machine learning studies that effectively predicted slide in laboratory quakes and apply it to sparse data from simulations. Transfer learning, in this context, refers to training the neural network on one type of data (simulation output) and then applying it to another (experimental data), with the extra step of training on a small subset of experimental data.
“Our lightbulb moment occurred when I realized we could apply this strategy to Earth,” Johnson explained. “We may model a seismogenic fault in the earth, then use the same kind of cross-training to include data from the actual fault for a section of the slip cycle.” The goal would be to forecast fault movement on a seismogenic fault like the San Andreas, where data is restricted due to rare earthquakes.
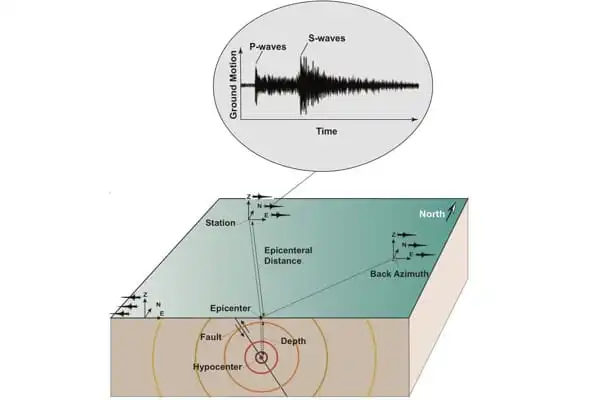
A typical seismogram of a minor earthquake was recorded quite close to the epicenter. The P-waves arrive first, followed by the arrival of the S-waves. The S – P interval is the time between the arrival of the initial P and S waves; it is used to calculate the distance from the epicenter). This interaction produces additional seismic waves (phases) that will be detected by seismographs.
The team began by simulating the lab quakes numerically. These simulations entail creating a mathematical grid and feeding in variables to replicate fault behavior, which is sometimes simply the best estimate.
The convolutional neural network used in this article included an encoder that reduces the simulation’s output to its main features, which are encoded in the model’s hidden, or latent space, between the encoder and decoder. These characteristics are the essence of the input data that can forecast fault-slip behavior.
The simplified features were processed by the neural network to estimate the friction on the defect at any given time. The model’s latent space was also trained on a short slice of experimental data in further development of this strategy. With this “cross-training,” the neural network effectively predicted fault-slip events when fed unseen data from another trial.















