Multi-Label Classification Multi-Label Classification is the definition of concepts for the quantification of the multi-label nature of a data set. It is a binary relevance, which simply…
Prosecutor’s Fallacy Prosecutor’s Fallacy is any of several fallacies of statistical reasoning often used in legal arguments. It can arise from multiple testing, such as when evidence…
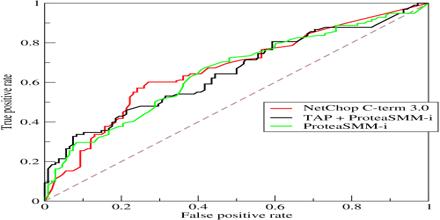
Receiver Operating Characteristic This article talks about Receiver Operating Characteristic, which is a graphical plot that illustrates the performance of a binary classifier system as its discrimination threshold…
Frequentist Probability Frequentist Probability concepts were introduced and much of probability mathematics derived, classical statistical inference methods were developed, the mathematical foundations of probability were solidified and…
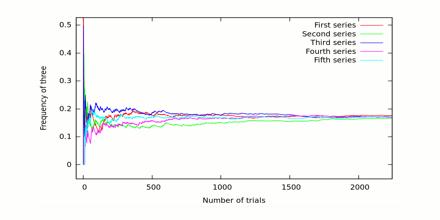
Pseudorandomness Process Pseudorandomness Process is the theory of efficiently generating objects that “look random” despite being constructed using little or no randomness. This Process is easier to…
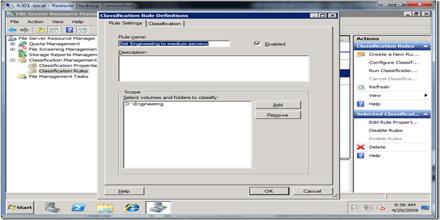
Classification Rule This article describe about Classification Rule, which is a procedure in the elements of the population set are each assigned to one of the classes.…
Statistical Classification Statistical Classification method used to build predicative models to separate and classify new data points. Statistical Classification is a classification having a set of discrete…
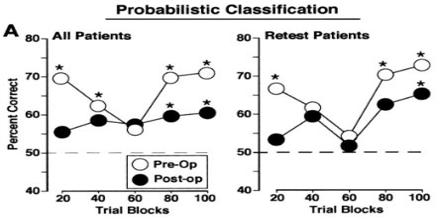
Probabilistic Classification This article describe about Probabilistic Classification, which in particular, the archetypical naive Bayes classifier, are among the most popular classifiers used in the machine learning…
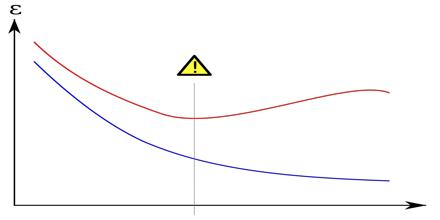
About Overfitting Overfitting generally occurs when a model begins to memorize training data rather than learning to generalize from the observed trend in the training data. Overfitting…
Semi Supervised Learning Semi Supervised Learning involves function estimation on labeled and unlabeled data. This approach is motivated by the fact that labeled data is often costly to…
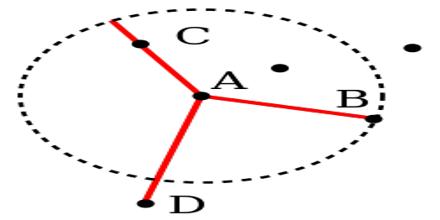
Local Outlier Factor Local Outlier Factor (LOF) is based on a concept of a local density. Local density is estimated by the typical distance at which a point…
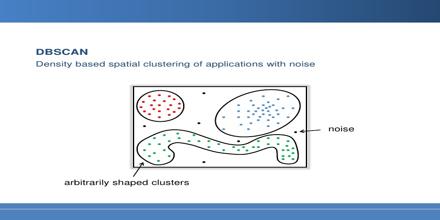
Density Based Spatial Clustering of Applications with Noise (DBSCAN) Density Based Spatial Clustering of Applications with Noise (DBSCAN) can identify clusters in large spatial data sets by looking at the local density of database…