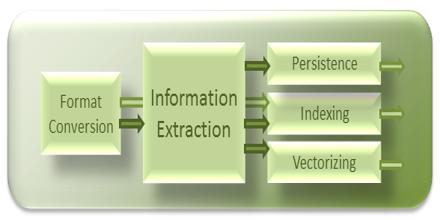
Information Extraction deals with the problem of text management. It is an automatic extracting structured information based task. Recent activities in multimedia document processing could be seen as information extraction. This article also focus on human language texts by means of natural language processing. The discipline of information retrieval (IR) has developed automatic methods. Another complementary approach is that of natural language processing (NLP). In terms of both difficulty and emphasis, IE deals with tasks in between both IR and NLP. We also define for any given IE task a template, which is a case frame to hold the information. An IE system is required to “understand” an attack article only enough to find data corresponding to the slots in this template.
Information Extraction