
Deep Learning, also known as ‘deep structured learning’, is a “machine learning” subfield that is concerned with algorithms inspired by the brain’s structure and a function called artificial neural networks. it is a key technology behind driverless cars, allowing them to identify a stop sign, or differentiate a pedestrian from a lamppost. Learning will be supervised, semi-supervised, or unsupervised. It’s the key to voice control in consumer devices like phones, tablets, TVs, and hands-free speakers. Lately and with good reason, deep learning is getting lots of attention. It’s producing results which were previously not possible.
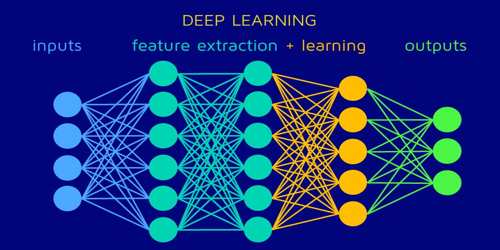
Inputs and Outputs of Deep Learning
Deep learning systems such as artificial neural networks, deep belief networks, recurrent neural networks, and coevolutionary neural networks have been implemented in fields such as computer vision, machine vision, speech recognition, natural language processing, audio recognition, social network filtering, machine translation, bioinformatics, drug design, medical image analysis, material inspection, and board game programs, where they need produced results resembling and in some cases surpassing human expert performance.
“Deep Learning is a superpower. With it, you can make a computer see, synthesize novel art, translate languages, render a medical diagnosis, or build pieces of a car that can drive itself. If that isn’t a superpower, I don’t know what is.”
– Andrew Ng, Founder of deeplearning.ai and Coursera Deep Learning Specialization.
He spoke and wrote a lot about what deep learning is, and is a good starting point. Andrew identified deep learning in early talks on profound learning in the sense of conventional artificial neural networks. According to Andrew, the essence of deep learning is we now have fast enough computers and sufficient data to actually train large neural networks. That as we construct larger neural networks and train them with more and more data, their performance continues to extend. This is often generally different to other machine learning techniques that reach a plateau in performance.
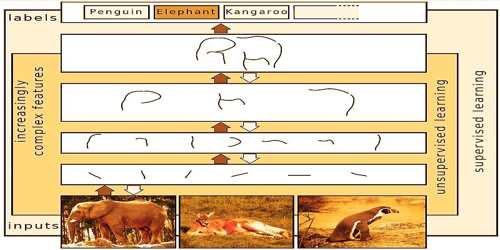
Multiple Layers of Abstraction in Deep Learning
In deep learning a computer, the model learns directly from pictures, text, or sound to perform classification tasks. In deep learning, the term “deep” comes from the use of several layers in the network. Deep learning models can achieve cutting-edge precision, often exceeding output at the human level. Models are trained by employing a large set of labeled data and neural network architectures that contain many layers. The layers are also enabled to be heterogeneous in deep learning and to deviate widely from biologically informed connectionist models for the sake of performance, trainability, and comprehensibility, whence the “structured” portion.
The first advantage of deep learning over machine learning is that the needlessness of the so-called feature extraction. Most modern deep learning models are focused primarily on artificial neural networks, Convolutional Neural Networks (CNN)s, although they can also include layer-wise ordered propositional formulas or latent variables in deep generative models such as nodes in deep belief networks and deep Boltzmann machines. Long before it was used, traditional machine learning methods were mainly used. Like Decision Trees, SVM, Naïve Bayes Classifier, and Logistic Regression.
Deep learning helps consumer electronics fulfill user expectations, and for safety-critical applications such as driverless cars, it is vital. Recent advances in deep learning have improved to the point that deep learning outperforms humans in certain tasks, such as image classification of objects. Importantly, a deep learning process may learn which features are required to optimally place themselves at which stage. More precisely, deep learning systems have a considerable credit assignment path (CAP) depth. While it was first theorized within the 1980s, there are two main reasons it’s only recently become useful:
- Deep learning involves large quantities of labeling data. For example, the creation of driverless cars involves millions of images and thousands of hours of video.
- Deep learning calls for tremendous computational power. High-performance GPUs have a parallel architecture which is useful for profound learning. Combined with clusters or cloud computing, this helps development teams to cut training time from weeks to hours or less for a deep learning network.
Deep Learning Methods for Cyber Security
Deep learning architectures may be constructed with a greedy layer-by-layer method. It helps to disentangle these abstractions and select which features improve performance. The “Big Data Era” of technology will provide huge amounts of opportunities for brand spanking new innovations in deep learning. Deep learning models tend to increase their accuracy with the growing amount of training data, while conventional machine learning models like SVM and classifier Naive Bayes stop improving after a saturation point. Andrew often mentions that we must always and can see more benefits coming from the unsupervised side of the tracks because the field matures to handle the abundance of unlabeled data available.
Deep learning models are trained using large sets of labeled data and architectures in the neural network that learn features directly from the data without the need for manual extraction. Apart from scalability, another commonly cited advantage of deep learning models is their ability to perform automated extraction of features from raw data, also called function learning. A key advantage of deep learning networks is that they often still improve because of the size of our data increases.
Deep learning excels in troublesome domains where the input (and even output) is similar. In other words, these are not a few amounts in a tabular format but rather images of pixel data, text data documents, or audio data files. The plausibility of deep learning models from a neurobiological perspective has been investigated through a variety of approaches. A successful deep learning application requires an awfully great amount of knowledge (thousands of images) to coach the model, yet as GPUs, or graphics processing units, to rapidly process our data.
Information Sources:















